

Hello! This is the first in a series of blog posts that will explore my experience developing a database-focused distributed application. My goal is to build a system that tracks the progress of a group of people sitting for a series of skill examinations.
Here’s how it works: a candidate makes an Attempt at an Evaluation, scored by an Evaluator, who submits an Outcome when the Evaluation concludes. These relationships won’t change, even if our application scales up to tens of thousands of users. That’s great, and something we’ll leverage when defining our database schema below.
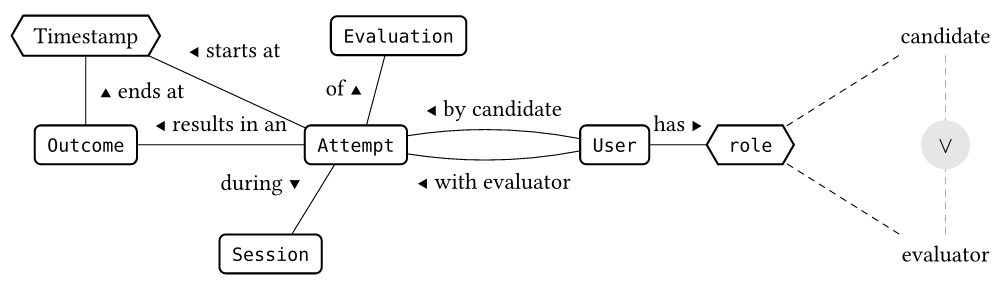
Figure 1: The data model for our application.
Our application should make it easier for Administrators to dynamically reassign resources like Evaluators and equipment while a Session is in progress. There's timeline pressure on development (surprise!) and corporate doesn't know whether they're willing to commit data infrastructure at the moment. But, it's got to be in the cloud, and the solution must be "agile” — so we're going to start from a point of broad compatibility and make sure we understand our requirements before making commitments.
In this blog post, we’ll look at how I evaluated potential solutions, why I decided SQLite Cloud was the best database for the job, and how I built a proof of concept for my app. If you like this, be sure to read Part 2 to find out how my app was received by my team, and how we iterated on our first solution!
Analyzing our requirements and picking a solution
Our application needs accurate, consistent, and available data. We don't want users, or their applications, to think too much about how the data they produce or consume will be interpreted. Applying rules and constraints to a centralized data store would help meet these goals. We know our application must live in the Cloud, so why not put our database there too?
But there are a million and one cloud database solutions nowadays–which one should I choose?
The first step toward answering that question is defining our requirements:
Access to some data will be infrequent, about hourly, while other data will be requested as frequently as 10 times/minute.
We want to articulate logical relationships in data using both definitions and structure.
Once a Session is complete, we want to archive the data in a "cold” access tier.
We need strong consistency in our data layer, but it does not need to be subsecond or real-time.
Given these requirements we can make a few reasonable assumptions:
READ and WRITE operations will peak at different times, likely in succession (e.g. one after another).
We can represent Figure 1 with a simple data schema.
Our schema allows us to aggregate (and disaggregate) individual Sessions.
Archived datasets preserve the definitions and relationships we will need to understand them later.
As for non-functional requirements, we have to implement quickly and the solution must scale up as necessary. Users will "bring their own device” so portability and compatibility are quite important. This is a weak list, yes, but we can refine it as we engage stakeholders and get a better sense of what features and functionalities are important to them.
Seems like a SQL database would meet our needs well. We know there are plenty of cloud SQL databases that support our use case that are fairly cheap to onboard and relatively easy to expand or relocate from over time. Perfect. Let’s think over what SQL can contribute to our effort.
Why SQL?
SQL allows us to describe relationships clearly and tersely, complete with constraints that apply to all interactions with our data. A consistent schema gives us confidence that whether our data originates from one database or many, the operations we apply to those data are accurate and repeatable. That the same queries work "in the palm of our hands” and at petabyte scale is a remarkable property of SQL databases we will take full advantage of.
Since we must support concurrent interaction by multiple users, it makes sense to define our schema in a composable and scale-friendly way. One group of tables are infrequently updated, while the others are updated at a higher rate—but only while one or more Sessions are in progress. Figure 2 incorporates the majority of these requirements. The schema isn't optimized, but it's straightforward and communicates our dependencies well. It’s early in the project and we have time refactor or renormalize as we engage stakeholders and learn more. Since Figure 2 captures the essential relationships expressed by Figure 1 we’re going with it.
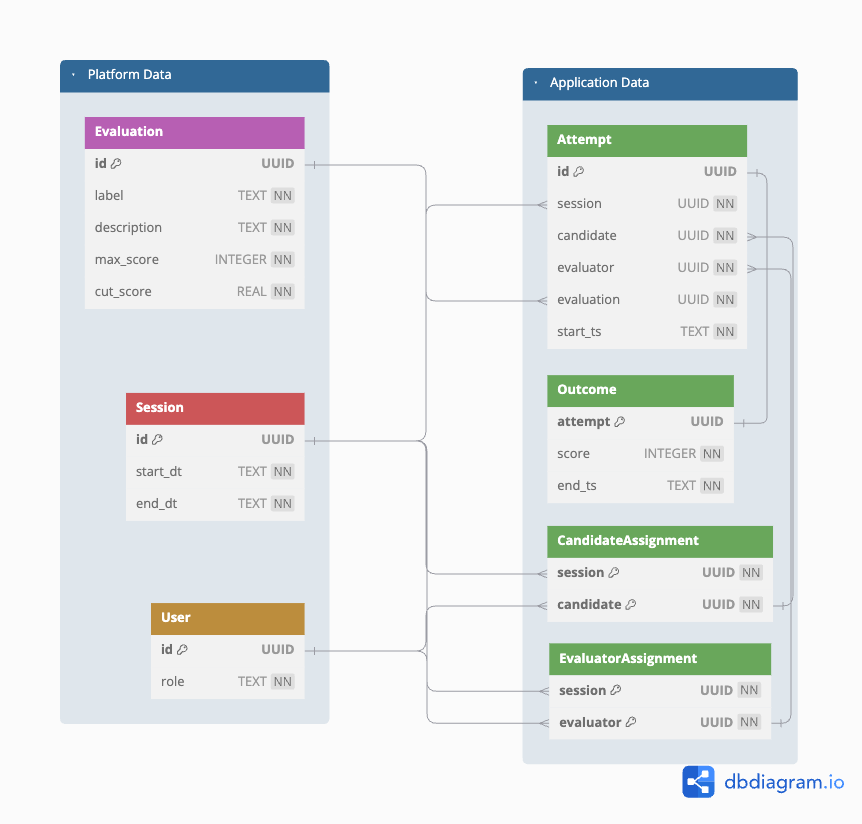
Figure 2: A SQL schema that aligns with our data model and meets our requirements.
Now that we've defined a data model, we need to pick a database technology. A local Postgres or MySQL instance is more setup, maintenance, and complexity than we need right now. A hosted solution would be better, but corporate wants to "see value” before committing resources and we'd like to bank time for development (over infra). It would be great if we didn't have to commit to the cloud, or a cloud vendor, straight away. Even better if "rolling off” a vendor's platform is low friction.
Ultimately we want users to access the Session database from their own device. We won't know whether they're bringing the latest tablet or an end-of-lifecycle phone and can't trust they will always be online. SQLite seems to make a lot of sense for this use case—could we leverage a cloud solution based round it? Let's evaluate whether SQLite is a good fit, then consider what features we may want from a Cloud provider.
Why SQLite?
In general our users will access the application (and its database) from personal devices. "Bring your own” adds a lot of potential compatibility and portability issues we'd rather not solve for. But SQLite runs just about everywhere, on just about any device. And because it's an orthodox relational database, we know the schemas and constraints our application relies on are portable. If we end up changing databases we won't be forced to refactor ⅗ of our application. Coding these rules and constraints into our application would take a lot of time–plus they'd be difficult to maintain–so we’ll bundle them with our data to add context and richness at low cost.
Can we deliver a more consistent platform experience without hardening the requirement that Users be connected? Seems realistic that with a touch of cloud services we can make a Session's data available to all Evaluators and Administrators whose devices can access the internet at least intermittently. An ideal solution would be a cloud-based, local-first SQLite database platform. Enter SQLite Cloud.
Why SQLite Cloud?
SQLite Cloud connects our SQLite database with users' devices in a safe and secure manner. We know it's built on mature technology and the SDKs require minimal changes to existing code—or knowledge— to use. We can do most of our design and testing offline without sweating compatibility or versioning Issues.
As our application scales, "nice to have” features like user data isolation, edge functions, webhooks, publish/subscribe, offline mode, and permission-based access will become less "nice” and more "essential”. Confining Session data to independent SQLite databases means there is no chance of lateral data leakage: we don't need to engineer safeguards or test for vulnerabilities that simply don't exist. Archive is straightforward because we can treat each database like a file and use a blob store. Plus a growing number of modern "big data” databases support direct ingestion of SQLite databases if we are inclined to scale up our Data Science.
SQLiteCloud is compelling because it allows us to flex our architecture without giving up the "really nice to haves” that SQLite brings to the table. We’ll build our application so it’s easy to switch between local and cloud. That will give us a good idea whether the approach is realistic, and a feel for how to work between local and cloud like we’ll want to later.
Building a Solution
Our application must solve a difficult, and classic, information-sharing problem. SQL helps with that by allowing us to define schemas that deterministically preserve essential relationships. SQLite enables us to store and access this information in a principled way. SQLiteCloud helps us add (many) more users to the party, with features that make it easier to implement a solution to our core problem.
Design and requirements gathered, let's roll them into an implementation. We’ll start by looking at the SQL and Python code that helps us track a Candidate's progress through a Session.
The Data Layer
Looking at Figure 2, we see a group of tables labeled Platform Data. We expect these data will be sourced from a global record system and have generated a batch to mock what our application needs (data/sessions_evaluations_users.sql). Our bootstrap script will load these data for us so we can focus on the Application group.
Tables in the Application Data group will be updated more frequently. We need to ensure these updates are precise and timely. Rules, constraints, and triggers will help us do that.
Let’s take a closer look at the tables in each Group, and how our schema (sql/schema.sql and Figure 2) specifies they interact.
Platform Data Table Group
The entities Evaluation, Session, and User (of two types) are the inputs our application "mixes” into an Evaluation Session. Each Session is populated by Evaluators' (Users with role=”evaluator”) assessments of Candidates (Users with role=”candidate”). Our application makes an entry in the Assessment table at the beginning of an evaluation, then an entry in the Outcome table at the end.
This mimics two fundamental behaviors of exam administration practice: (1) you must be on "the list" ahead of time to be admitted, and (2) each evaluation has a distinct start and end time. Our "list(s)" are the tables CandidateAssignment and EvaluatorAssignment, which specify the Candidates and Evaluators assigned to each Session. Assessment and Outcome assign a timestamp by default. It would be helpful to add more robust constraints, since both Candidates and Evaluators are registered as Users and it is not (yet) guaranteed times are recorded accurately. We’ll start to address these items once we look at the other Table Group.
Application Data Table Group
Let's examine the function of each table in this group to get an idea of how they interact.
| Table | Functional Description |
Attempt | Mapping between the entities (Session, Candidate, Evaluator, Evaluation) that indicates a Candidate started an Evaluation at a particular date and time. |
Outcome | The Evaluator's score for an Attempt, which indicates the Evaluation ended at a particular date and time. |
CandidateAssignment | Mapping of Session to Candidate. Our application's source of truth for determining whether a Candidate is allowed to participate in a Session. |
EvaluatorAssigment | Mapping of Session to Evaluator. Our application's source of truth for determining whether an Evaluator is allowed to participate in a Session. |
Table 1: Functional description of the tables used by our application.
Table 1 communicates that we will update CandidateAssignment and EvaluatorAssigment infrequently. It also tells us the relationship between Attempt and Outcome contributes the preponderance of complexity to our application. No surprise, as the interaction between those entities is a classic problem in computer science: resource locking. Ugh. Let's see what we can do to lower the angle of approach by applying additional rules and constraints to our data layer.
The file sql/validation-triggers.sql defines a set of TRIGGER functions that add robustness to data integrity. We have two types of User—Candidates and Evaluators—and we need to make sure our application doesn't mix them up. Policies, and sometimes laws, say that one Candidate cannot view another's data. If our application thinks a Candidate is an Evaluator, we might be at risk of leaking sensitive information. Let's define some TRIGGER functions that ensure our application never makes this mistake!
| TRIGGER | Description |
candidate_assignment_is_candidate | Check that a User's ID has role ‘candidate' prior to writing to the table CandidateAssignment. |
evaluator_assignment_is_evaluator | Check that a User's ID has role ‘evaluator' prior to writing to the table EvaluatorAssignment. |
attempt_candidate_in_session | Check that a User's ID has role ‘candidate', and the User is assigned to the Session prior to writing to the Attempt table. |
attempt_evaluator_in_session | Check that a User's ID has role ‘evaluator', and the User is assigned to the Session prior to writing to the Attempt table. |
Table 2: Description of the TRIGGER functions that ensure our application doesn't mix up Candidates and Evaluators.
With TRIGGER functions in place, our database will refuse any INSERT that fails to satisfy more nuanced rules. It will be helpful to add a few more that maintain the integrity and order of the data we collection on an individual Candidates Evaluation.
| TRIGGER | Description |
attempt_evaluation_exists | Check that the Evaluation exists prior to writing an entry to the Attempt table. |
attempt_candidate_has_no_ongoing_evaluations | Check that a Candidate is not assigned to more than one Evaluation ("double booked”) at any given time. |
outcome_end_ts_gt_attempt_start_ts | Check that the end time for an Outcome is greater than the start time of the Attempt it pairs with. |
Table 3: Description of the TRIGGER functions that ensure our data remain logically consistent.
These TRIGGER definitions appear expensive. Let's take a closer look at them before moving on.
| TRIGGER(s) | Considerations |
candidate_assignment_is_candidate and evaluator_assignment_is_evaluator | Query the User table on each INSERT. This will need to change as we scale up. For now, we'll keep the User table small and minimize the number of INSERTs to CandidateAssignment and EvaluatorAssignment. |
attempt_candidate_in_session and attempt_evaluator_in_session | Query much smaller tables of a fixed size. Both tables have two (2) primary keys, which speeds lookup. Since these data do not change the database to perform some optimizations "in place” over the course of a Session. Ultimately we’ll want to relocate this logic, for now it is more important we enforce it. |
attempt_evaluation_exists | Query the Evaluation table before each INSERT into Attempt. We can refactor this into a CONSTRAINT over time. |
attempt_candidate_has_no_ongoing_evaluations | Query the Attempt and Outcome tables prior to each INSERT into Attempt. It’s a windy one but very important. For now we’ll consider expensive justified and revisit this area when we can focus. |
outcome_end_ts_gt_attempt_start_ts | Query the Attempt table prior to each INSERT into Outcome. Critical to maintaining the integrity of records and not too expensive for a small dataset. We’ll probably refactor this later, but keep this low on the list. |
That covers our data layer. We even wrote a nice bootstrap utility to set it up in a SQLite or SQLiteCloud database with a single-line change!
Time to implement a passable solution to the resource locking problem. We'll show our work in Python and feel good that SQLiteCloud has SDKs for five (5) more languages (and counting) should we need to pivot.
Emulating User Behavior
We will rely on a relatively small amount of Python code to mock the behavior of Users during a Session. The problem we're solving (resource locking) is recursive, so it behooves us to keep our implementation t
erse. Mercifully this code is not slated for production. We need it to get our application up-and-running so we'll eschew optimizations and focus on making sure the output is repeatably accurate.
Every Candidate in a Session must attempt each evaluation once. However, a Session may end before all Candidates have had the chance. We’ll save the case of "What about Candidates who don’t finish?” for later. For this sprint it will be enough to ensure that each Evaluation has minimal downtime.
Candidates cannot be in two places at once, either. The database does some work to prevent this state, but as a safety feature: our implementation is the first line of defense. Our class keeps track of Candidates who in an Evaluation, and which Evaluations each Candidate has completed. Doing so minimizes the chance of generating invalid data, which is sufficient for this sprint.
Start-to-finish, these are the steps we’ll take to populate a Session.
Assign Evaluations
Assign Evaluators
Assign Candidates
See to it as many Candidates can visit as many Evaluators as possible
Conclude evaluations once the End Time is reached
Item 1 is easy. We have a fixed number of Evaluations (6) and will use all of them every time. This is not quite realistic, but it doesn't make sense to add complexity right now.
Item 2 is made easy by assigning one (1) and only one Evaluator to each Evaluation and not allowing changes. This allows us to sidestep some complexity by manually designating that Evaluation == Evaluation. This is good enough for now but we'll want to refactor this relationship so many Evaluators can administrate a single Evaluation.
# Assign a single Evalutor to each Evaluation
for (i, evaluation) in enumerate(evaluations):
evaluation["evaluator"] = evaluators[i]
associated_evaluations.append(evaluation)
populate_session.py (138 to 144)
Item 3 is quick to implement with a Python set and its pop method. Not the approach we'll want long-term, but a "cheap” way to ensure uniqueness works for now.
for session in sessions:
session = session[0]
session_evaluators = []
session_candidates = []
# ...
for _ in range(0, random.randint(min_candidates, max_candidates)):
candidate = candidates.pop()
session_candidates.append((session, candidate))
Item 4 and Item 5 are more involved. Concurrency is complex to model so we'll be terse (take a look at the code if you'd like more!). We use a round-robin approach to pair an available Candidate with an available Evaluator. Because the implementation is naive, we allow a number of retries to ensure a high degree of matching. Once a match is made, we sample times for the evaluation and a reset period independent Gaussian distributions. If an Evaluator assesses all Candidates prior to the Session's end, they wait for the Session to finish. Otherwise the Session ends and some Candidates will not have finished. (Remember that this isn't a case we'll handle just yet.)
See utils.MockSession.run for the full implementation.
Now that we have a way to dynamically populate a Session, let's put the dashboard together!
The Data Dashboard: Showing Our Work
We're going to use Observable notebook to accelerate development. They are reactive and come with built-in support for SQLite, npm, and user interface widgets. We can upload a SQLite database or connect with SQLiteCloud using the JavaScript SDK. Just like our Python application, we can rapidly transition to the cloud as our implementation nears maturity.
We don't need much to make the dashboard: a selector for Sessions, a visually appealing summary table, and some code to glue them together. Ours is simple, functional, and visually appealing—what's not to love?!?
Take a look at the Dashboard for Data Apps with SQLite Cloud - Part 1!
"Zooming in” for a moment, we can see that it's trivial to switch between SQLite


And SQLiteCloud
We've reached our last milestone! Our code works, our dashboard looks great, and both can switch between SQLite and SQLiteCloud by changing a single line. Pretty cool!
Validating Constraints and Triggers
Our application appears to be working, and that feels great. Let's parlay our excitement into writing tests—so we know it actually works—then book a demo! The schemas we defined above spell out what we need to verify rather nicely.
| Definition | Description | Test |
candidate_assignment_is_candidate | Check that a User's ID has role ‘candidate' prior to writing to the table CandidateAssignment. | Try to insert an Evaluator's ID into CandidateAssignment. |
evaluator_assignment_is_evaluator | Check that a User's ID has role ‘evaluator' prior to writing to the table EvaluatorAssignment. | Try to insert a Candidate's ID into EvaluatorAssignment. |
attempt_candidate_in_session | Check that a User's ID has role ‘candidate' and the User is assigned to the Session prior to writing to the Attempt table. | Try to insert an Evaluator's ID into Attempt.candidate. |
attempt_evaluator_in_session | Check that a User's ID has role ‘evaluator' and the User is assigned to the Session prior to writing to the Attempt table. | Try to insert a Candidate's ID into Attempt.evaluator. |
attempt_evaluation_exists | Check that the Evaluation exists prior to writing to the Attempt table. | Try to insert a UUID that is not in Evaluation.id into Attempt.evaluation. |
attempt_candidate_has_no_ongoing_evaluations | Check that a Candidate is not assigned to more than one Evaluation ("double booked”) at any given time. | Try to insert the ID of a Candidate who is already engaged in an Evaluation. |
outcome_end_ts_gt_attempt_start_ts | Check that the end_ts for an Outcome is greater than the start_ts of the Attempt it pairs with. | Try to assign a DateTime to Outcome.end_ts that is less than or equal to Attempt.start_ts. |
The majority of CONSTRAINTS may be tested by either (1) submitting a random UUID, or (2) populating a valid database then attempting to DELETE rows.
Tests for our CONSTRAINTS and TRIGGERS are implemented in test_constraints_and_triggers.py.
Improvements and Upgrades
We've met our first deliverable and seen how easy it is to use SQLite as an onramp to SQLiteCloud. Check out the repository on Gitlab and Observable notebook to give it a try or put your own spin on it!
What about those Upgrade Opportunities we flagged? Our application is fully compatible with SQLite Cloud, and we'll refine it using these features in upcoming posts!
Edge Functions and WebHooks to give Evaluators independence
PUB/SUB to improve concurrency
Offline Mode to strengthen reliability
Thanks for reading, and happy hacking!







